系統設計面試架構圖
照著架構練習跟回答通常表現會比較好
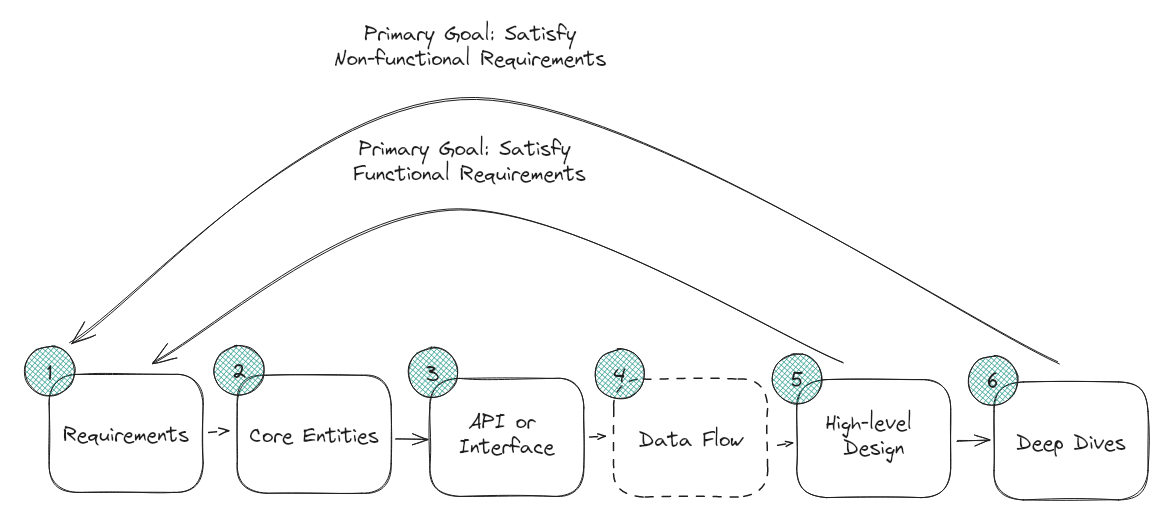
Requirements (~5 minutes)
釐清問題是重要的第一步
Functional Requirements
簡單來說就是「這個產品有什麼功能」,要找出功能性需求,就必須反覆跟面試官討論,最後討論的結果可能會像是:
- 使用者可以發布推文
- 使用者可以追蹤其他用戶
- 使用者可以看到自己追蹤的人的更新內容
要記住,這階段所找出的需求是你等等系統設計時要解決的,所以不能太發散、太廣,找出核心重點的功能來解決就好。
Non-functional Requirements
非功能性需求應該要量化,像是:
- 延遲應該要 < 500 ms
而不是
- 延遲要低
這邊的需求不是能做到什麼,而是「有什麼期望」,像是:
- 系統應該高可用且可用性大於一致性
- 系統要能夠承受 1 億每日活躍使用者(DAUs)
- 低延遲,渲染速度低於 200 ms
非功能需求會比較難想,我們可以利用以下清單來發想:
- CAP Threorem:Consistency 與 Availability 權衡取捨,Fault Tolerance 在分布式系統中是默認具備的,這點要留意。
- Environment Constraints: 環境有任合條件跟限制嗎?邊緣端?手機?網路或記憶體有限制?
- Scalability:系統會需要在特定條件下擴張嗎?黑色星期五?對於系統來說讀跟寫哪種需求更大?
- Latency:能夠接受多大的延遲?對於有意義的需求,要特別考慮,像是 google 搜尋結果的輸出
- Durability:資料遺失對系統來說重不重要?社群媒體可能可以接受部分資料遺失,但對於銀行系統來說就不行
- Security:系統要多安全,這要考慮資料保護、存取控制、規範
- Fault Tolerance:系統的容錯性應該多好?冗余、容錯移轉、復原這些都是可以考慮的選項
- Compliance:是否有業界規範、法律需要遵守?
Capacity Estimation
雖然很多教學可能會說要進行 back-of-the-envelope calculations(粗略計算),但通常這是不必要的,做計算的時機只有在那些計算對系統至關重要時才做,像是:
計算出在不同雲服務提供商下存儲 100TB/天 的成本
以及長期儲存這些視頻所需的總成本
並考慮是否需要設計更高效的壓縮和刪除策略來降低成本。
假設流量大部分來自北美和亞洲。你可以計算每個地區的高峰時段流量,以此來決定 CDN 節點的部署策略。
在面試環節時可以先跳過此環節,並說明當有需求時再回來計算。
Core Entities (~2 minutes)
找出系統中核心的實體,這些實體是主要用來交換、儲存的資料模型,面試過程時簡單的記下這些實體即可,隨著我們的設計進行,我們可以快速迭代並添加新的實體到清單中。
以 Twitter 來說,核心的實體可能會是:
- User
- Tweet
- Follow
API or System Interface (~5 minutes)
通常在這個環節,我們會依照我們前面功能需求所定義的,去設計一組供使用的接口。
有幾種常見的選擇:
- RESTful API
- GraphQL API
- Wire Protocol(自定義)
通常 RESTful API 就已經可以滿足大多數的需求了,GraphQL 只發生在讓客戶端自行搜尋所需的資料以避免 over-fetching or under-fetching,而如果需要雙向互動諸如 websocket 的話,資料傳遞的格式就必須自行定義了。
[Optional] Data Flow (~5 minutes)
如果系統會執行繁雜的資料操作,像是資料處理系統,那麼透過簡單的列表來說明資料大致會經過什麼流程是有幫助的,但如果相反,你的資料處理相對單純,那直接跳過此步驟沒關係。
用網頁爬蟲舉例:
- 獲取 URLs
- 解析 HTML
- 萃取 URLs
- 儲存資料
- 重複
High Level Design (~10-15 minutes)
在這個環節,我們可以將常見的 components 用線、方塊來表示並連接在一起來滿足我們前面提到的功能、非功能性需求,注意,重點是滿足前面所討論的需求,不要過度思考跟複雜化問題。
通常我們會一個一個 API 檢視,從功能性需求開始著手,然後是非功能性需求,一個個建立相對應的設計來滿足需求,你的系統設計會從一個很簡單的樣貌開始逐步添加直到滿足需求。
在繪製系統時,要與面試官討論思考過程,明確表示資料如何流經系統以及狀態如何變化,從 request 開始並結束在回傳 response,當資料流到持久層時,是一個好時機紀錄該實體可能會有什麼欄位,不用太具體,紀錄有相關的欄位就好,但具體是什麼資料類別並不重要。
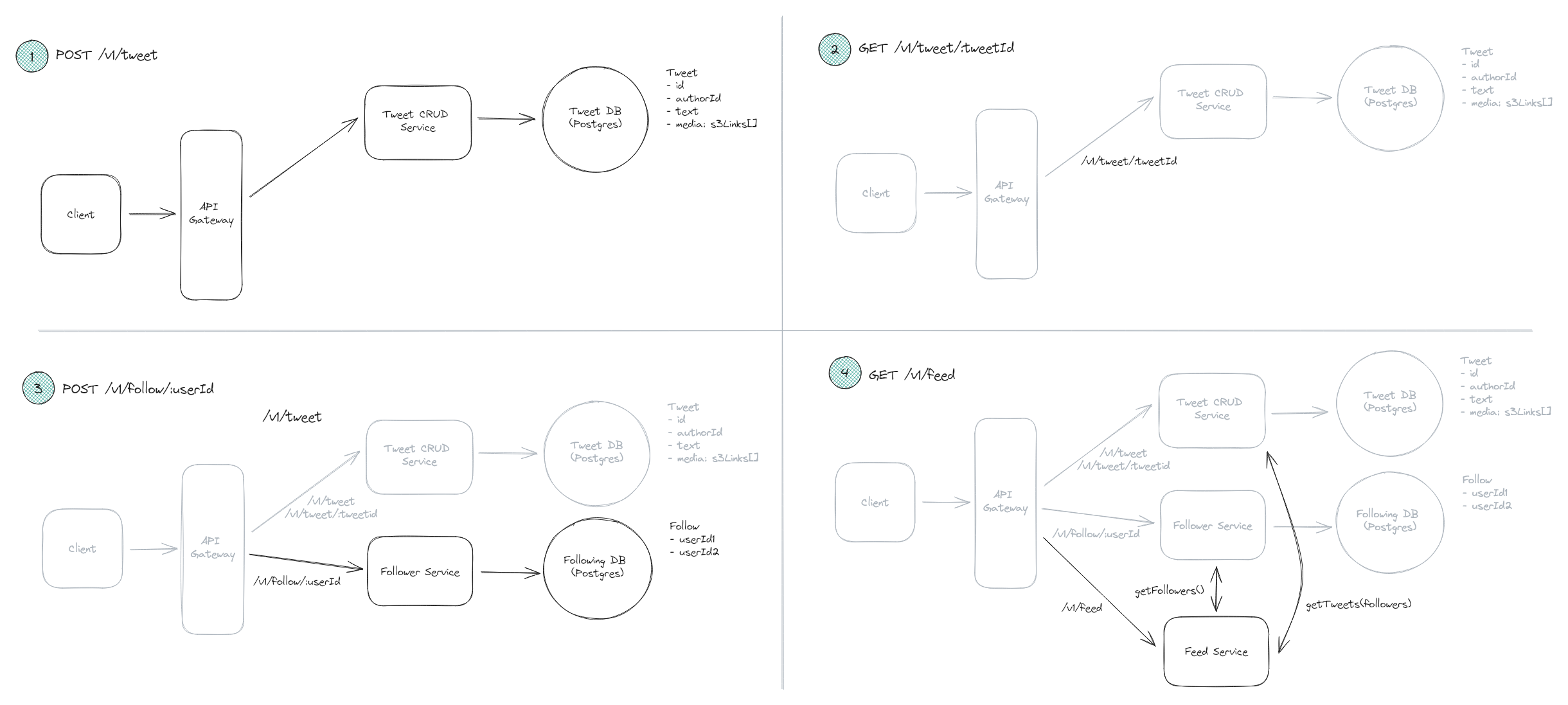
用 Twitter 的 4 個 API 來說明,可以看見我們一個一個的進行 API 設計,並逐步迭代我們的設計
Deep Dives (~10 minutes)
在上述的環節,一定有很粗糙跟不夠好的地方,我們要做的就是在這個環節優化他們,但要留意以下幾點
- 確保有滿足非功能需求
- 處理邊緣情況
- 識別 & 解決問題、瓶頸
- 根據面試官的反饋優化答案
較為初階的面試者會等待面試官的回饋,但高階的面試者應該會自己找到可能的問題並引導討論。
舉例來說,Twitter 的範例接下來可能會討論要如何滿足 > 100M DAU,那可能討論會聚焦於水平擴張、快取、db sharding,並隨著討論逐步更新。