系統設計核心觀念 (2)
Indexing
索引,就像字典會有索引目錄一樣,是一種用來幫助你快速找到想要的資料的資料結構,在大多數系統中,我們可以接受寫入慢一點,但我們不能接受讀取很久,所以良好設計的 index 相當重要。
一個簡單粗暴的方式是使用 hash map,$O(1)$ 就可以找到想要的資料,但當資料海量時,維護一個這麼大的 hash table 可能佔用相當多記憶體。
另一個方式是將資料排序儲存,這讓我們可以使用 binary search 來 $O(log\ n)$ 找到資料,而這也是最常見的方式。
還有很多不同方式,但概念是透過一些前置步驟來大幅加快之後搜尋資料的速度。
大多數討論 index 的時候還是跟資料庫比較相關,根據資料庫的不同,我們有不同的 indexing 策略,大多數關聯式資料庫可以讓我們針對一個欄位或一組(多個)欄位來建立索引,這對搜尋速度會造成相當顯著的差異。
儘管有些 DB 會提供你客制 index ,但如果 DB 本身有提供,建議是直接使用現成的,這些現成的策略都經過大量的實戰驗證,絕對會比你自己從零打造來得好。
Specialized Indexes
除了一些常見的 index,像是 B-tree、Hash,也有比較特別的像是
- geospatial indexes: 專門用來搜尋地理位置的索引,像是:最近的餐廳、最近的加油站等等的
- Vector databases: 專門用來搜尋高維度的資料,像是:找類似的圖片、文件
- full-text indexes: 專門用來搜尋文字資料,像是:搜尋文章、推文
上述大多的 index 現有的 DB 就有支援,根據 CMU 教授的說法「與其考慮新穎、特殊的資料庫來解決上述的需求,不如先考慮用既有成熟的 DB 然後附加插件去解決」。
儘管如此,但對於上述的需求,作者推薦 ElasticSearch 作為二級索引的解決方案,上述三者都有支援,我們可以透過 Change Data Capture (CDC) 來讓 ElasticSearch 集群根據 DB 的變化隨之更新,聽起來很美好,但電腦科學一切都是取捨,加上一個新的 component 同時也增加了一個可能 failure 的點以及延遲,並且從搜索索引中讀取的數據可能不是最新的,不過,如果你需要強大的搜尋功能以及可以容忍輕微延遲,那 ElasticSearch 是一個很好的選擇
補充: 除了主鍵之外的索引都稱作二級索引
Communication Protocols
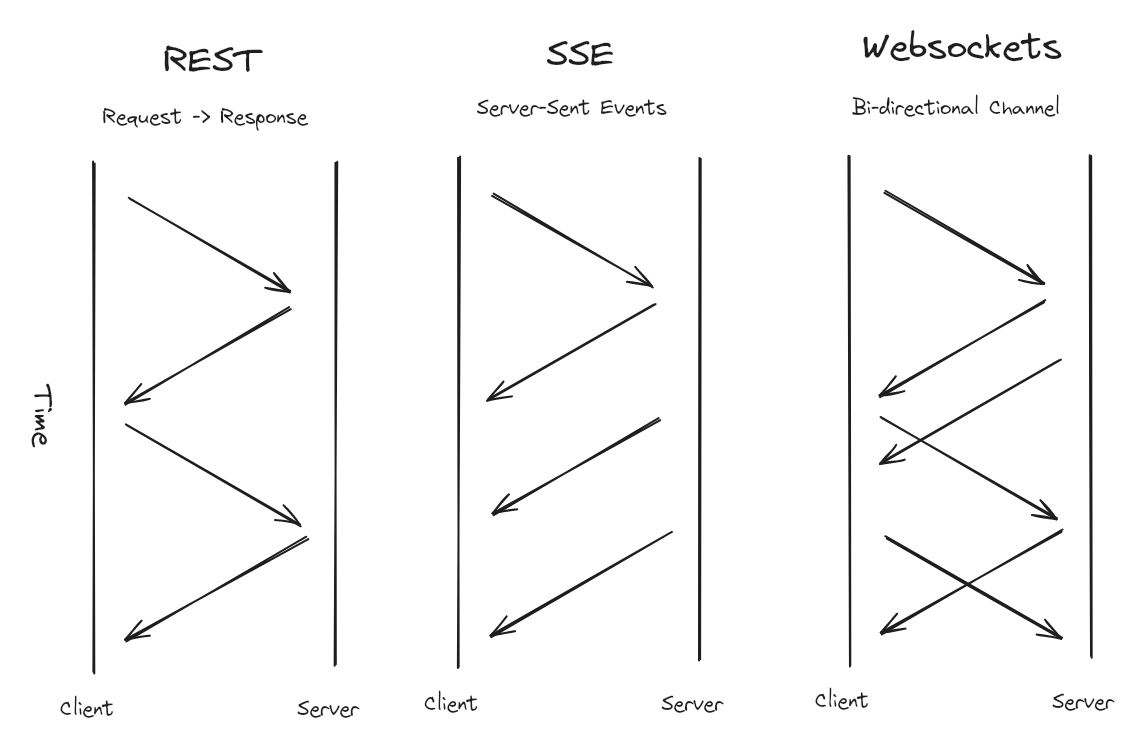
溝通的方式主要就兩種:對內 or 對外,對內通常比較單純,使用 RESTful HTTP 跟 gRPC 可以處理大多數的場景,對外就必須考慮使用者會怎麼使用你的服務、誰先發起連線、延遲的程度、有多少資料要傳輸,儘管如此,但大多數情況用以下 4 種可以解決
HTTP
簡單的一個 request 一個 response,如果有 follow RESTful API 設計,你的 API 應該是 stateless 的,我們可以使用一個 load balancer 後面部署多個服務,簡單的做到水平擴張
SSE
Server Send Events 在應對 server 單方向推送更新至 client 的場景很好用,就像 WebSocket 一樣,透過維持一個持續的 HTTP 連線,當有更新時就主動推送至 client-side,不過 client-side 是不能推送資訊到 server 這邊的,這使得 SSE 更容易實現並整合到現有的 HTTP 基礎架構中,例如負載平衡器和防火牆,而不需要特殊處理
跟 WebSocket 最大的差異就是通訊方向,SSE 是單向而 WebSocket 是雙向,適合單方面傳輸資料的場景,像是: 股價更新、即時通知
Long-Polling
要認識 Long-Polling,就要先知道 polling,polling 在做的事就是每隔一段時間送出一個 request,很簡單但這樣很浪費資源,因為你要求資料的時候可能後台根本還沒更新,Long-Polling 針對這一點做出改善,當今天 client-side 送出請求時,如果 server-side 沒有可用的更新資料,我們就將連接保留著,直到 server-side 有更新時再回傳或是逾時回傳,此時這個連接功成身退,我們就可以將它關閉
比起 SSE,Long-Polling 需要消費更多資源,因為每次請求都還是需要建立連接,相當不適合大量即時資料傳輸的場景,不過對於一些低頻的請求,或是兼容舊系統,Long-Polling 還是有他應用的空間
WebSocket
在當前實時相關的需求中,常見的一個選項是 WebSocket,透過在一條 TCP 連線上提供雙向、full duplex(數據可以同時在兩個方向上傳輸)的資料傳輸,這讓我們可以做到即時的資料交換,但天底下沒有白吃的午餐,除了 server 需要支持外,有些 firewall 跟 proxy server 可能會阻止 WebSocket 連接,如何維護許多連線也可能是一個挑戰。
一個常見的做法是使用 message broker 來處理客戶端和伺服器之間的通信,然後後端服務都與 message broker 進行通訊,如圖下
graph TD
C1[WebSocket 客戶端 1] -->|WebSocket| WS[WebSocket 服務]
C2[WebSocket 客戶端 2] -->|WebSocket| WS
C3[WebSocket 客戶端 3] -->|WebSocket| WS
WS --> MB[Message Broker]
MB --> WS
MB -->|訂閱| S1[後端服務 1]
MB -->|訂閱| S2[後端服務 2]
S1 -->|發布| MB
S2 -->|發布| MB
style C1 fill:#f9f,stroke:#333,stroke-width:2px
style C2 fill:#f9f,stroke:#333,stroke-width:2px
style C3 fill:#f9f,stroke:#333,stroke-width:2px
style MB fill:#ff9,stroke:#333,stroke-width:4px
style S1 fill:#9ff,stroke:#333,stroke-width:2px
style S2 fill:#9ff,stroke:#333,stroke-width:2px
在系統面試中,通常不會要求你客制一個傳輸協定,我們用既有的即可。
比較 SSE & long polling & WebSocket
| 特性 | SSE (Server-Sent Events) | Long-Polling | WebSocket |
|---|---|---|---|
| 通訊方向 | 單向(伺服器 → 客戶端) | 單向(伺服器 → 客戶端) | 雙向 |
| 連接模式 | 持續連接 | 斷續連接 | 全雙工持續連接 |
| 協議 | HTTP/HTTPS | HTTP/HTTPS | WebSocket 協議 (ws/wss) |
| 延遲 | 低 | 中等 | 最低 |
| 數據效率 | 高 | 低 | 最高 |
| 伺服器負載 | 低 | 中 | 中等 |
| 瀏覽器支持 | 大多數現代瀏覽器 | 所有瀏覽器 | 大多數現代瀏覽器 |
| 適用場景 | 單向即時更新 | 簡單即時通訊 | 雙向、即時互動 |
| 典型應用 | 新聞推送、股票更新 | 聊天應用(早期) | 即時聊天、遊戲、協作工具 |
狀態
狀態 (state) 是系統複雜性的主要來源。如果可能的話,將狀態存放在像消息代理(message broker)或資料庫這類外部系統中,能夠簡化系統設計。這樣可以使你的服務保持無狀態 (stateless),並且可以水平擴展 (horizontal scaling),同時仍然可以與客戶端保持狀態化的通訊。
具體來說,我們可以將狀態儲存在外部系統中,像是 Message broker(RabbitMQ、Kafka)或 Database,來解耦合資料與服務邏輯本身,以下是一個例子:
假設你有一個電商系統,客戶在瀏覽商品時可能會將商品添加到購物車。傳統的方式可能是將購物車狀態保存在應用服務器內存中,這會導致服務器重啟或增加更多實例時出現問題。為了解決這個問題:
- 狀態外部化:將購物車的狀態存儲在 Redis 這樣的快取數據庫中或消息代理中。這樣,每次請求都可以獨立處理,不同的服務實例只需要讀取 Redis 或消息代理中的狀態即可處理客戶的購物車操作。
- 保持無狀態服務:服務本身不需要存儲購物車的狀態,因此可以自由擴展,隨著流量增加自動擴展實例數量,而不需要考慮狀態同步問題。
這種架構使系統既簡單又可擴展,適合高並發、分佈式系統的場景。